本記事の内容
私が作ったWebサイトの内容
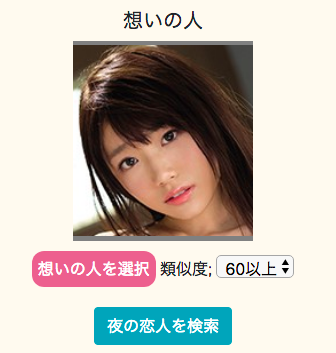
今回、私が作成したサービスは、画像をアップロードすると、類似のAV女優を探し出してくれるというものです。
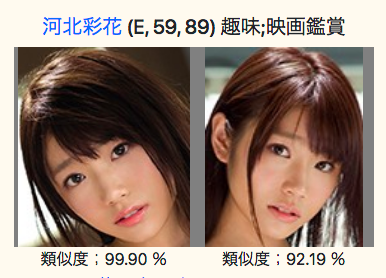
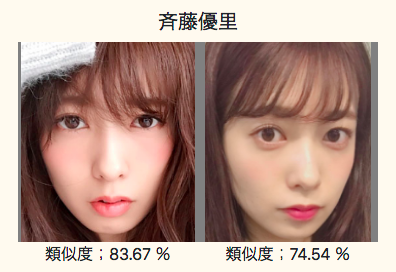
アップロードした写真は河北彩花です。
それに対して、同じ写真は類似度が99%と表示されているのは当然として、別の写真も92%と表示されています。
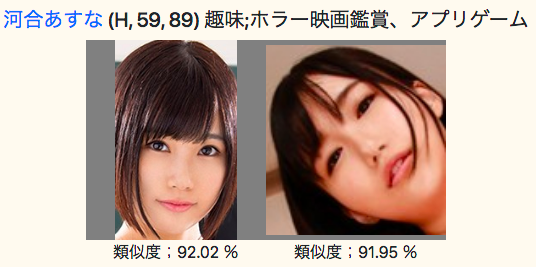
「永井みひな」や「河合あすな」も類似度が90%以上と表示されています。
確かに似ている気がします。
AWS Rekognitionは素晴らしいサービスです。

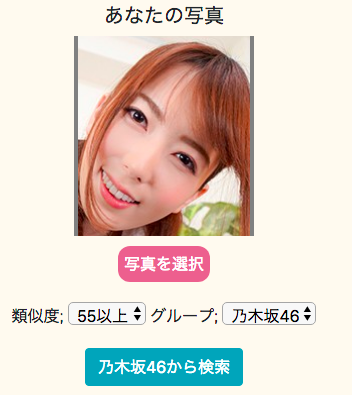
姉妹サイトで、乃木坂46を検索するサイトも作成しました。
こちらがアップロードした写真です。
結構、似ている気がします。
Webサイトを停止した理由
成果物に対してはかなり満足したのですが、このサイトは停止することにしました。
理由はRekognitionの値段が高いからです。
Image APIを通して画像を1,000枚処理すると、150円ほどかかります。
今回、女優のデータベースには100人ほど登録しました。
それは、一回の画像の検索で100回のAPIを投げることを意味します。
すると、一回の検索で15円ほどかかってしまいます。
個人でやる分には、リスクの高いサイトだなと判断して止めることにしました。
Webサイトの設計
ただし、折角なので記録は残しておこうかと思いたって、この記事を書くことにしました。
今回の大きな設計ポイントは、以下のようになります。
- AWSにCollectionを作成して、そこに画像を作成する。
- AWSのCollectionに対してAPIを投げて、結果を取得する。
- DMMのAV女優APIに問い合わせをして、趣味やアフィリエイトリンクを取得する。
では、順番に説明していきます。
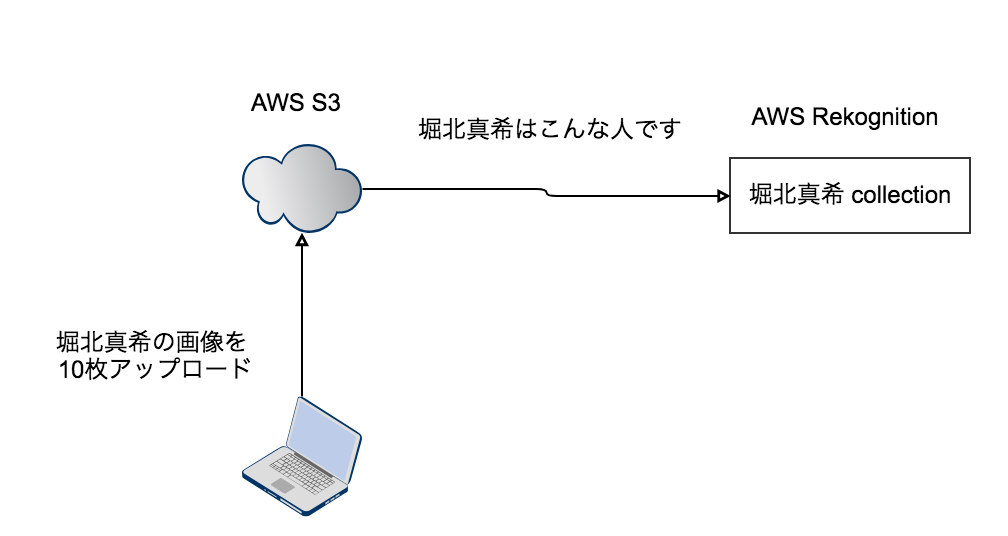
AWSにCollectionを作成して、Collectionに画像を登録する
AWS Rekognitionで画像を検索するためには、Collectionを作成してやる必要があります。
Collectionには、対象物を入れます。
例えば、「堀北真希」を画像で検索したいとします。
そのさいには、まずは「horikita」というCollectionを作成してやり、そこに「堀北真希」の画像を登録する作業が必要になります。
「horikita」というColllectionに対して多くの画像を登録すればするほど、「堀北真希」を判断する精度は高くなるはずです。
実際の作業ですが、まずはS3上にバケットを作成します。
バケットとは、画像を保存する場所のようなものです。
通常は、ドメイン名を使います。
今回は、このように定義しました。
bucket_name="s3://imagine-sweetheart.com" aws s3 mb $bucket_name
次に、バケットに堀北真希の画像をアップロードします。
aws s3 sync $source $bucket_name --acl public-read
そして、そのアップロードした画像をCollectionに登録してやります。
response = client.index_faces()
今、説明した作業を図にすると、このようになります。
AWSのCollectionに対してAPIを投げて、結果を取得する
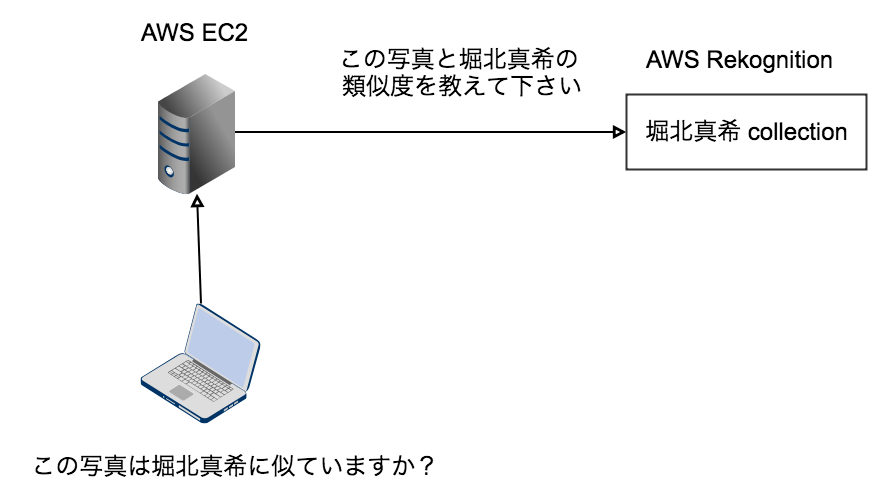
次は、出来上がったCollectionに対して検索をします。
堀北真希に似た知人の写真をAWS Rekognitionになげてやれば、類似度が返ってきます。
response=rekognition.search_faces_by_image()
DMMのAV女優APIにAPIを投げて、趣味やアフィリエイトリンクを取得する
機能的には上の2つだけでもよかったのですが、最後に表示するAV女優の趣味とアフィリエイトリンクが欲しかったので、DMM APIも使用することにしました。
コードの解説
こちらのレポジトリにAWSにCollectionを作成する部分のソースコードをアップロードしました。
./s3.sh
このコードでバケットを作成して、ローカルにある画像をS3にアップロードしています。
create_collection_and_register_face.py
このコードで、ローカルにある複数の画像をCollectionに登録してやります。Collection名は、ローカルのディレクトリ名と同様にしました。
こちらのレポジトリでは、AWSに画像検索とDMMにAV女優検索のAPIを投げています。
def upload():
Flaskを使っており、このコードが起点になっています。
最初の方の処理は画像の加工をしています。
- 検索したい画像をアップロード
- 画像の圧縮
- 画像のバリデーション
- 画像をS3に保存
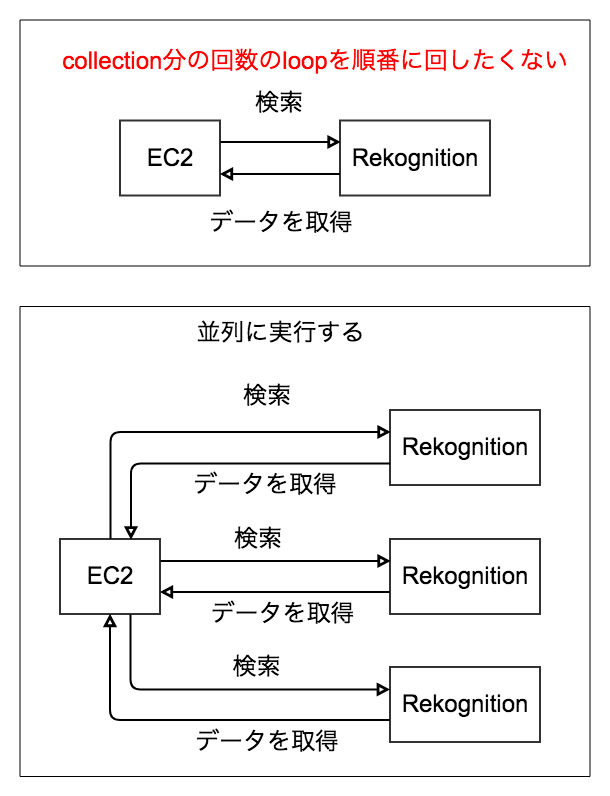
次にAWS Rekognitionに検索のAPIをなげるところですが、ここは少し工夫をしました。
通常のloop処理でAPIをなげると時間がかかってしまうからです。
Collectionの回数分だけAPIをなげる必要があり、今回であれば100人のAV女優をCollectionに登録したので、100回のAPIをなげる必要があります。
ただ、それを順番に待っているのは時間の無駄なので、並列処理を行うことにしました。
その処理がここです。
cmd = ['/usr/bin/python3','/var/www/html/bin/async_find_girl_and_dmm.py', file_name, threshold]
それが終わった後で、line 100行目辺りからDMMのAPIを呼び出して、スリーサイズ、趣味といった情報を取得しています。
str = 'https://api.dmm.com/affiliate/v3/ActressSearch?api_id=' str += DMM_APPID + '&affiliate_id=' + API_AFFILIATE_ID + '&hits=4&' str += 'keyword=' + urllib.parse.quote_plus(girl_name_ja, encoding='utf-8') str += '&output=json' dmm_data = urllib.request.urlopen(str)
以上で、簡単ながらソースコードの説明を終わります。
コード量はそれなりにありますが、実際のところかは大したことはやっていません。
最後に一つ。
このサービスを作る上で、一番、大変だったことはCollectionに登録する顔写真を手動で集めることでした(笑)
本格的にやるなら、その作業を自動化しないと駄目ですね!
Good luck with your engineer life!
この記事が面白かった人は、こちらの記事も読んでみて下さい。
-

-
Pythonの学習でおすすめの本と動画【2024年最新】
目次1 関連記事の紹介2 動画教材3 初心者向け【入門編】4 中級者向け5 上級者向け 関連記事の紹介 自然言語処理については、この記事を読んで下さい MLOpsについては、この記事を読んで下さい 機械学習については、この記事を読んで下さい ...

-

-
機械学習で何ができますか?【医療からキュウリの選別まで】
機械学習という言葉をよく耳にしますが、それで何ができるのでしょうか? 目次1 機械学習でできること2 まとめ 機械学習でできること 顔の検出 画像の中にある顔を検出することができます。 顔の分析 性別、「目が開いているかどうか」、「笑ってい ...

-

-
AWSの学習でおすすめの本と動画【2024年最新】
目次1 動画教材2 資格編(クラウドプラクティショナー)3 資格編(ソリューションアーキテクト)4 入門者向け5 中級者向け 動画教材 AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得 ▼ ...